炒股上杠杆 Meta浙大校友让评估模型「自学成才」,数据全合成无需人工标注,训练Llama 3 70B超过405B
发布日期:2024-10-15 21:34 点击次数:91
点评:当前的经济增长和通胀还不足矣让美联储下定降息的决心
据CME美联储观察显示,美联储2月维持利率在5.25%-5.50%区间不变的概率为97.9%,降息25个基点的概率为2.1%。到3月维持利率不变的概率为58.3%,累计降息25个基点的概率为40.9%,累计降息50个基点的概率为0.8%。今晚凌晨将迎来美联储今年首次议息会议,市场预计在本次会议上,美联储维持利率不变,市场聚焦于晚些时候美联储鲍威尔在新闻发布会上的讲话,交易者期待从鲍威尔讲话中寻找关于降息的更多线索。

编辑:乔杨
【新智元导读】随着LLM不断迭代,偏好和评估数据中大量的人工标注逐渐成为模型扩展的显著障碍之一。Meta FAIR的团队最近提出了一种使用迭代式方法「自学成才」的评估模型训练方法,让70B参数的Llama-3-Instruct模型分数超过了Llama 3.1-405B。
LLM在开发周期的每个阶段都依赖强大的评估模型,比如训练阶段用于对齐人类偏好或迭代自我改进的奖励模型,以及推理阶段作为人类评估的替代方案。
构建评估模型往往依赖大量的高质量人类偏好数据,不仅耗时长、成本高,而且在模型扩展到新任务或评估标准时造成了阻碍。
此外,随着新模型不断迭代改进时,现有的标注数据往往会过时,因为其中的评估是基于旧有的、性能较差的模型相应。这意味着需要不断重复上述的数据标注和收集流程。
最近,Meta FAIR发表的一篇研究就尝试使用合成数据的方法来解决这个问题。他们提出了一种迭代的自我训练方法,在训练循环中完全不使用人类标注的偏好数据,而是纯粹依赖合成数据。

论文地址:https://arxiv.org/abs/2408.02666
实验中,这种方法将Llama-3-70B-Instruct在RewardBench上的准确率从75.4提升至88.7,超过了使用人类标注数据的方法。
arXiv页面显示,这篇论文最后修订于8月8日,目前作者还没有公开相关代码。
方法概述
整个pipeline的流程大致如下(图1):
- 初始化:收集大量人类编写的用户指令,这在生产系统中较为常见,以及初始的种子LLM
- 指令选择:用LLM从数据集中选择出具有挑战性的、平衡的用户指令分布
- 响应对构建:对每个用户指令,通过提示创建LLM模型响应偏好对,让其中一个的质量(被拒绝响应)略低于另一个(被选择响应)
- 迭代训练:每次迭代包括两个步骤,判断标注和模型微调。
(i) 对每条数据采样N个LLM-as-a-Judge生成的推理链和判断结果。如果其中包含正确判断,则将该数据加入训练集,否则丢弃这条数据。
(ii) 在本次迭代构建的训练集上微调模型
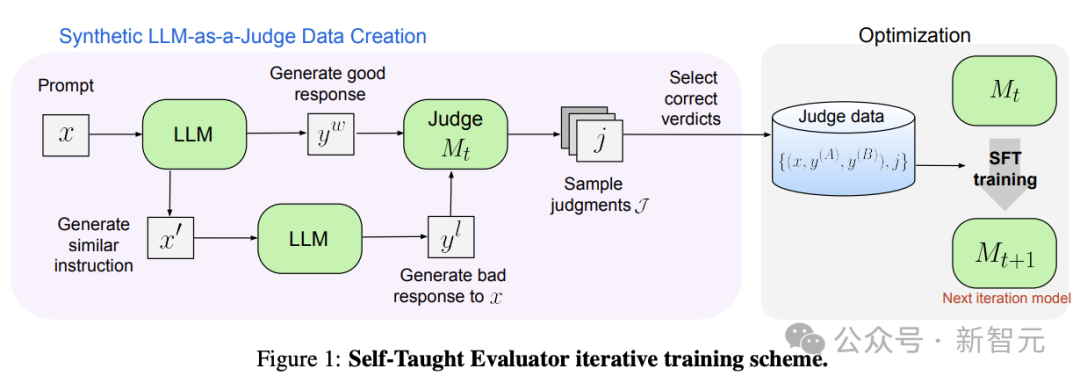
值得注意的是,每次训练迭代中,训练集大小取决于当前模型的质量。预计随着模型能力的提升,能够生成更多正确的判断,训练集大小也会逐步增加,从而构成了一个自学过程。
指令选择
之所以要进行指令选择,是因为生产系统中收集的用户数据可能存在大量噪音,模型响应的主题、多样性、难度和能力都有很大程度的不平衡。
因此,这一步骤的目标是筛选出特定分布的指令子集,用于生成高质量的响应和判断结果。
如图7所示,先给出精确的提示让LLM对每个输入进行分类,构建数据集时就可以在这些类别中「按需取用」。

响应对构建
经过前两步我们得到了一个精心构建的训练数据池。这一步骤就是要对其中每个输入xi,生成涉及到两个响应yiw、yil的偏好数据,其中前者yw(winning)的质量预计会优于后者yl(losing)。
但这一步完全使用合成数据而非依赖人工标注,那么如何保证yw和yl的响应质量差异?
论文提出了一种比较巧妙的方法,即先让LLM根据指令xi生成基线响应yiw;然后指示模型生成一个「嘈杂」版本的指令xi′=ϕ(xi) 。xi'与xi语义高度相关但不完全相同,之后生成对应xi'的模型高质量响应yil。
对于同一个指令xi而言,yil的质量预计会低于yiw。由此,我们构建出了一条完整的训练数据:
ei := xi, yiA, yiB
其中,w=A或w=B是随机分布的,且在最后的训练集构建中保证两种情况出现次数均衡,这对消除LLM-as-a-Judge的位置偏见非常重要。
判断标注
对于每条训练数据ei,LLM-as-a-Judge模型都会生成N个多样化的评价 𝒥:={ji1, …, jiN},然后应用拒绝采样过滤掉𝒥中与事实标签不一致的判断结果。实验中,N被设置为15。
若𝒥过滤后为空,该条数据在本次迭代中直接被丢弃。
若𝒥不为空,则从正确判决中随机选择一个,构建最终用于微调的训练数据:
(xi, yiA, yiB, ji)

实验中还尝试使用多数投票机制代替单个模型进行LLM-as-a-Judge判断,根据之前的研究结论,这可以带来性能改进。
实验及评估
初始模型M0从Llama-3-70B-Instruct进行初始化,每轮迭代i=1,…T中,使用Mi-1生成偏好数据并作为LLM-as-a-Judge模型进行判断,然后再次微调M0模型(即Llama-3-70B-Instruct)。
其中,指令微调利用了fairseq2库,并使用vLLM进行推理。
大量人类编写的指令数据{xi}来自WildChat数据集,指令选择步骤中使用Mixtral 22B×8进行分类,共筛选出了20,582个有挑战性的指令。响应生成步骤同样使用Mixtral 22B×8模型。
评估结果
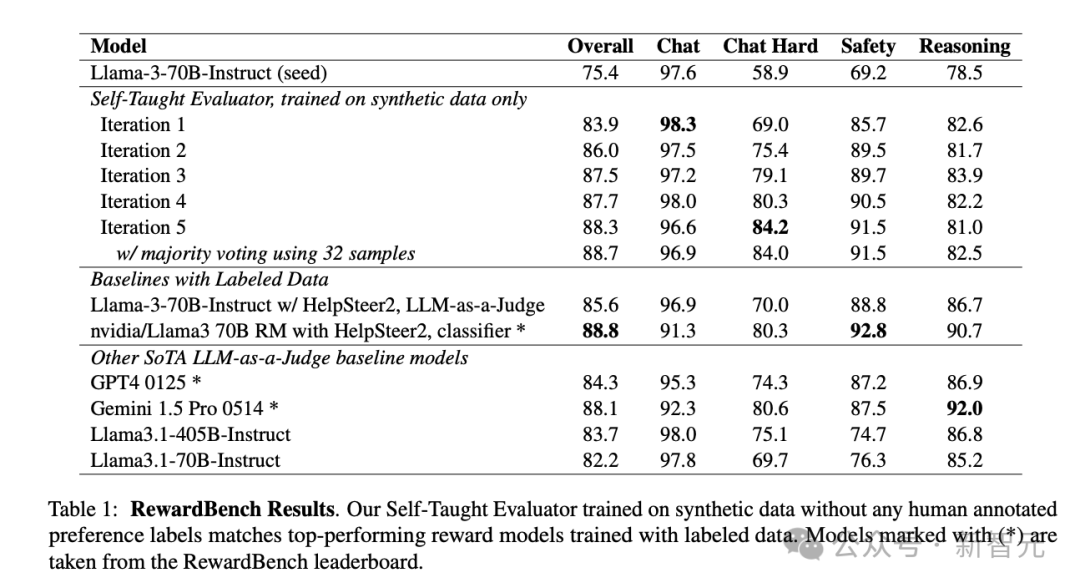
在RewardBench上的分数如表1所示。与种子模型相比,总分从75.4显著提升至88.7,超过了GPT-4和Gemini 1.5 Pro,甚至也超过了405B参数的Llama模型,而且好于使用人类标注数据集HelpSteer2的85.6分。
4个类别分别来看,Chat Hard和Safety的分数随着每轮迭代都有稳步上升,但Reasoing和Chat类别较为波动。Chat类别在训练后的分数甚至低于种子模型,作者推测,这是由于筛选的合成数据过于偏重困难任务。
此外可以发现,在LLM-as-a-Judge模型生成判断时使用32个样本进行多数投票的确可以提升整体性能。
HelpSteer2由英伟达和ScaleAI合作创建,是一个帮助模型响应变得更加事实正确且连贯的开源数据集。
仓库地址:https://huggingface.co/datasets/nvidia/HelpSteer2
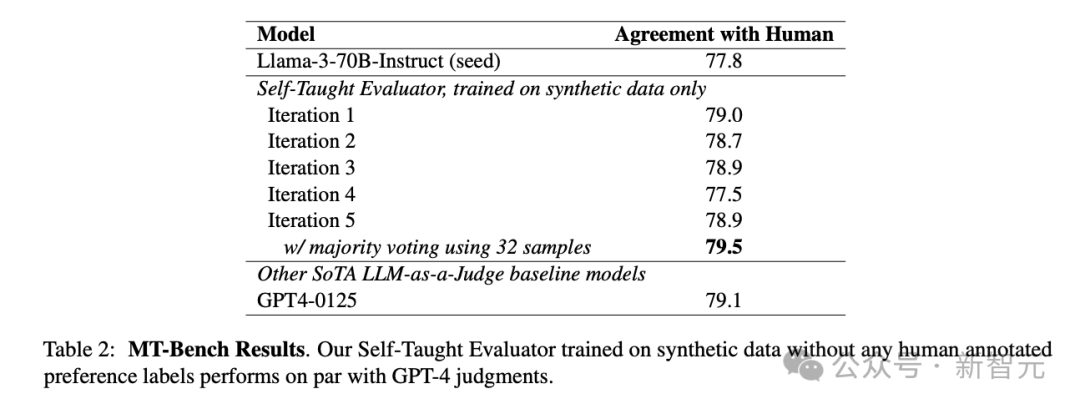
在MT-Bench上的评估结果如表2所示。虽然分数在第4轮迭代出现一些波动,但训练后的分数依旧有小幅度提升,与GPT-4相当。
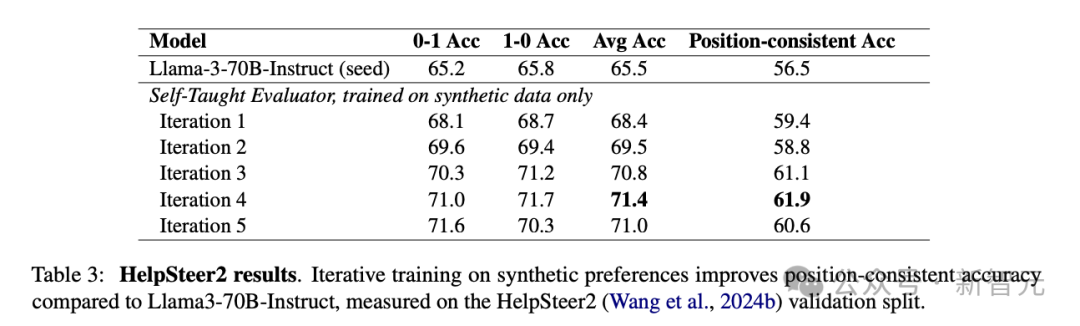
根据在HelpSteer2上的评估结果(表3),在合成数据上的训练也提升了模型作为judge进行判断时的平均精度和位置一致精度,但似乎最佳结果出现在第4轮迭代,多一轮迭代后反而降低了性能。
结论
总体来看,本文提出了一种可扩展的方法,在不使用任何人工标注数据的情况下构建响应偏好对,在此基础上训练的「自学评估模型」相比种子模型有显著的性能提升。
作者提出,该研究还存在一些未讨论的问题和局限:
- 第一轮训练迭代时,直接使用种子模型生成第一批偏好数据,但这背后的假设是Llama-3-70B-Instruct已经有生成合理评估的能力;论文并没有验证该假设是否成立
- 只使用了Llama-3-70B-Instruct作为种子模型进行实验,没有探究该方法对较小模型的适用性
- 在LLM-as-a-Judge的判断中,只研究了成对评估这一种模式;其实模型也可以直接评估单个响应的指令的质量
- 相比只输出分数的奖励模型,生成式的LLM-as-a-Judge还需要输出推理链,更长的输出会提升推理成本
作者介绍

Tianlu是Meta FAIR的一名研究科学家炒股上杠杆,她本科毕业于浙江大学计算机科学专业,博士毕业于弗吉尼亚大学。Tianlu的研究主要关注机器学习模型中有关公平性、稳健性和问责制的主题,特别是在计算机视觉和自然语言处理系统中。
栏目分类